The Basics and Core Concepts of Kafka
Introduction
What is Apache Kafka?
Apache Kafka is an open-source stream-processing platform designed to handle real-time data feeds with high throughput, fault tolerance, and scalability. Initially developed by LinkedIn, Kafka has become a critical component in data infrastructure, enabling organizations to build robust, real-time data pipelines and streaming applications. Kafka’s architecture is built around the concept of distributed commit logs, allowing it to handle vast amounts of data efficiently and reliably.
Kafka Components
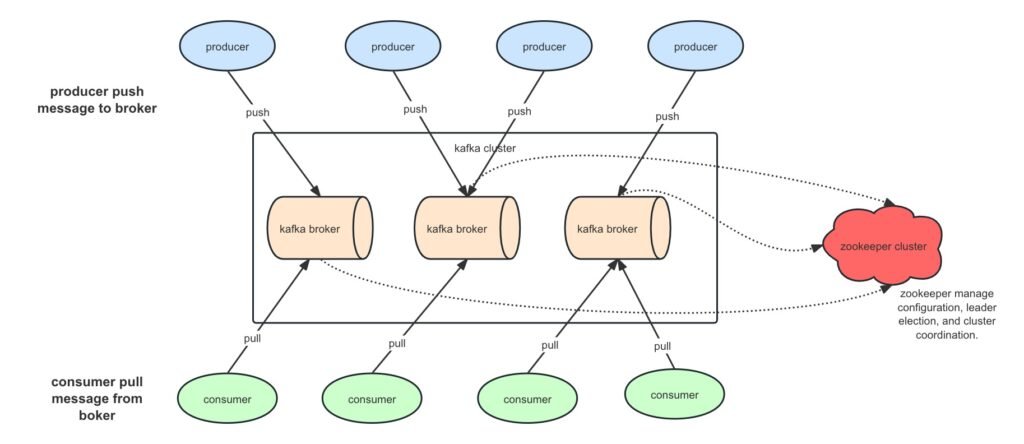
Producers
Producers are client applications that send data to Kafka topics. Their primary responsibility is to publish messages to the Kafka cluster, ensuring that the data is delivered accurately and efficiently.
Producers use the Kafka Producer API to send data to topics. They can specify the partition to which a message should be sent or let Kafka determine the partition based on a partitioning strategy. Producers typically serialize the data into a format that Kafka can store, such as Avro, JSON, or Protocol Buffers, before sending it.
Consumers
Consumers are applications that read data from Kafka topics. They process and transform the data based on the specific needs of the application, making it available for downstream systems.
Consumers use the Kafka Consumer API to subscribe to one or more topics and pull data from the assigned partitions. Kafka ensures that each consumer within a consumer group reads a unique set of partitions, enabling parallel data processing and load balancing.
Topics
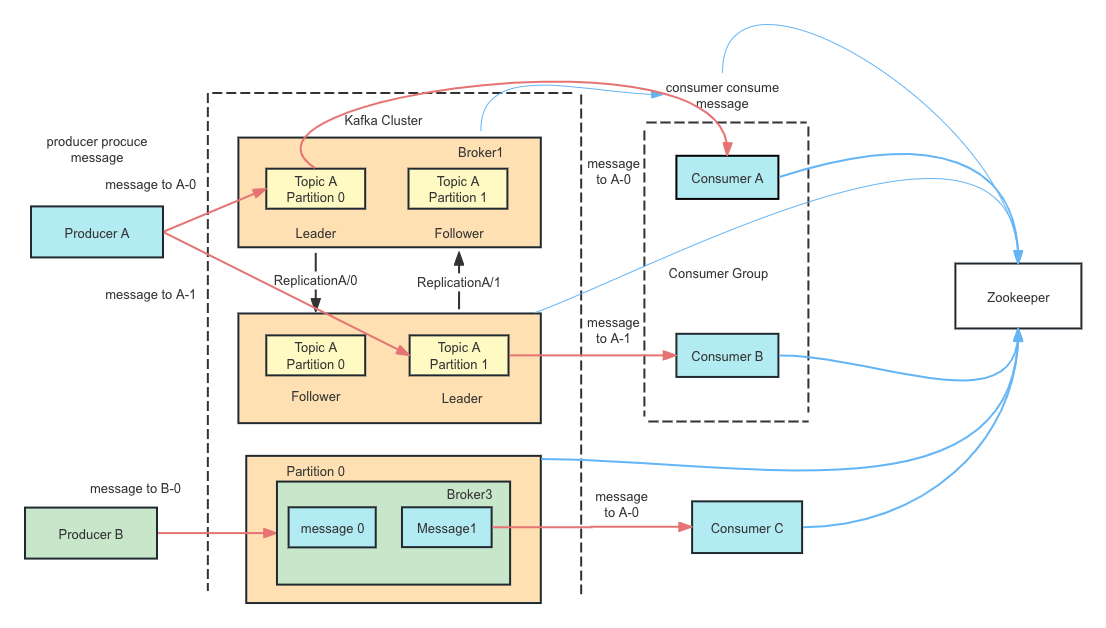
A topic in Kafka is a logical channel to which producers send data and from which consumers read data. Topics are divided into partitions, each of which is an ordered, immutable sequence of records that Kafka appends to.
Topics are essential for organizing data streams in Kafka. They allow different types of data to be separated and processed independently, improving data management and streamlining data workflows.
Partitions
Partitions are the fundamental units of parallelism in Kafka. Each partition is a sequence of records, and Kafka maintains the order of records within a partition.
Partitioning allows Kafka to scale horizontally by distributing data across multiple brokers. It also enables parallel processing, as multiple consumers can read from different partitions simultaneously, increasing throughput and performance.
Kafka Cluster Components
Brokers
Brokers are Kafka servers that store data and handle requests from producers and consumers. Each broker manages one or more partitions and is responsible for storing and retrieving data.
Brokers store data in partitions and replicate it across multiple brokers for fault tolerance. They handle client requests and ensure data is written to and read from the appropriate partitions efficiently.
Zookeeper
Zookeeper is a centralized service used by Kafka to manage configuration, leader election, and cluster coordination. It ensures that brokers are aware of each other and that data is distributed correctly.
Zookeeper tracks the status of Kafka brokers and maintains information about the partitions and their replicas. It coordinates leader elections for partitions and helps manage the state of the cluster, ensuring high availability and fault tolerance.
Kafka Data Flow and Storage
Message Production Process
Producers send data to Kafka by publishing messages to a specified topic. The messages are serialized and partitioned, and Kafka ensures they are stored in the appropriate partitions across the brokers.
Message Consumption Process
Consumers subscribe to topics and pull data from the assigned partitions. Kafka tracks the consumer’s offset, which is the position in the partition where the consumer has read up to, ensuring that data is processed in order.
Commit Log
The commit log is a fundamental component of Kafka’s architecture. It is an append-only log where records are stored in the order they arrive.
The commit log ensures data durability, as records are written to disk and replicated across multiple brokers. This replication mechanism provides fault tolerance, ensuring that data is not lost in case of broker failures.
Data Replication and Fault Tolerance
Replication Mechanism
Kafka partitions have a leader and multiple follower replicas. The leader handles all read and write requests, while followers replicate the data.
Replication ensures that data is available even if some brokers fail. Followers can take over as leaders in case the current leader fails, maintaining data availability.
In-Sync Replicas (ISR)
In-Sync Replicas (ISR) are the replicas that are fully caught up with the leader. They are critical for maintaining data consistency and durability.
Kafka ensures that data is only acknowledged as committed once it has been replicated to all ISRs. This guarantees that all replicas have the latest data, maintaining consistency across the cluster.
Fault Tolerance Strategies
Kafka’s architecture is designed for high fault tolerance. By replicating data across multiple brokers and using Zookeeper for coordination, Kafka can handle broker failures seamlessly.
When a broker fails, Kafka’s leader election process ensures that a new leader is chosen from the ISRs. This process minimizes downtime and ensures continuous data availability.
Conclusion
Apache Kafka is a robust platform for handling real-time data streams. Its core components—producers, consumers, topics, partitions, brokers, and Zookeeper—work together to ensure data is processed efficiently and reliably.
Kafka’s ability to handle large volumes of data with low latency and high fault tolerance makes it indispensable for modern data processing needs. Understanding its architecture and core concepts is essential for leveraging its full potential in building scalable, real-time data pipelines and applications.